目录
蓝图
虽然上回说道可以开始写代码了,但其实我们都知道写代码和写作文一样,是需要立提纲的。 所以不妨让我们先拿出一张纸和一支笔,列下助手需要的功能。(天灵灵地灵灵,PM 快点上我身)
鄙校教务系统和天下所有政企网站一样,完全不把交互体验放在眼内,例如:
- 可怕的评分系统:你要我先评老师再看成绩我不怪你,但能不要让人一次填几百个选项么
- 缺乏一个绩点计算系统:每次评比的时候都需要我小鹿乱撞地复制那个成绩到某个 exe 里面,好麻烦呢!
- 老是登录不上,跳转到一个莫名其妙的错误页:给谁看呢?
- ...(多不胜数的意思)
根据这些吐槽我们可以整理出以下几个功能点:
- 一键评分(老师不会细看我们的评分那我给个总体分就好了吧)
- GPA 计算器(麻麻再也不用担心班委按计算器按成狗 :doge: 了)
- 错误页自动跳转
P.S. 想拥有更多功能?请猛戳 issue 目录进行添加!
重构第一步:从结构入手
我们先看重构前的代码(内容从下面开始包含若干不负责任吐槽,请未成年人在监护人陪同下观看):
程序最开始的入口就是 init 这里:依次进入各个函数,然后分别检查当前页面是否是对应功能执行的目标。
这里马上就能发现一个可以改善的地方:不应该让子程序去找我们,而是让我们去主动找子程序。 这样的话可以去除子程序中冗余的操作啦。(有点那么个 mediator 的意思啦)
所以第一行代码我们先写一个操作执行管理器:Page.
然后代码的结构就可以变成类似这样的形式:
var page = new Page;
page.on('成绩查询页面', function () {
// 给这个页面加上好用的 GPA 计算功能!
});
page.on('教师评价页面', function () {
// 随手按给老师打个分!
});
page.on('我都不知道什么情况的错误页', function () {
// 解决这个错误咯
});
是不是有种“复行数十步,扩然开朗的感觉呢”!
第一个功能
确定好结构以后,我们可以把目光移向真正的功能啦,为了好好享受暑假,我决定从比较简单的做起: GPA 计算器。 (不过后来发现假如预先做好错误页自动跳转会多么的幸福啊 QAQ)
根据助手第一个版本,我们很快地就按照正常人的思维:
- 获取课程列表中的所有成绩
- 每个(行)课程计算出对应的绩点、学分绩点;插入到该行中
- 计算所有课程的平均绩点、平均分和加权平均分;插入到表头中
- 监听鼠标时间,取消/勾选某个课程的时候重新计算(重新执行 3)
写出了这样的代码。
然后打包这新增加的 163 行代码,放到浏览器里进行人工测试:

Recap 1
虽然代码能运行,但其实有很多潜在问题。如果直接按照上面的思维来写的话,很容易就把计算功能和页面处理功能混淆在一起; 代码也就变成和 DNA 双螺旋结构一样的形式:各部分紧紧耦合(大家还记得 DNA 两条链是怎么连接的么?)。
这在软件开发中是很明显的 bad smell 噢! O.O
另外一个问题就是代码变得不太容易测试。写过浏览器插件的同学都应该知道,这种和具体行为紧关联的代码是很难进行测试的, 只能通过人手进行测试,所以会让你的开发流程变成:
- 写写写 / 改改改
- 打包
- 刷新页面,查看效果;发现问题?回去 1
当你遇到像鄙校教务系统一样的网站的时候,也真是醉了。_(:з」∠)_
所以接下来我们要重构这段用来重构的代码(递归开始)。
FYI: 什么鬼是 code smell?
看这里;看完分分钟变敏捷开发狗 :doge:。
第一个重构
重新审视上面的代码,我们可以发现写出来的代码可以分为两部分:
- 计算
- 修改页面
修改页面这个涉及到具体的页面效果,所以还是比较适合进行人肉测试; 而计算部分其实是很好做单元测试的,所以我们接下来就应该大刀阔斧地抽离这部分的逻辑。
程序 = 数据结构 + 算法, 好程序 = 好数据结构 + 准确的算法
有关数据结构的名言就不搬了,对程序进行抽象的一个显而易见方法就是使用对的数据结构。 在助手这个 case 里,我们不妨先把每门课程抽象成一个简单的属性集合 —— 这样课程数据立刻变成了生猛的、区别明显的实体了。(好吧又是我脑补的,画面有些惊悚。)
而具体的 GPA 计算我们也应该抽离出一套策略,大家使用策略就好,不用关心提供者怎么实现这个策略。(另外一层抽象)
根据上面的分析我们可以分离出如下两个大头:
- Lecture: 用于记录课程信息
- GPA: GPA 计算策略提供者
// ## GPA 计算器
var GPA = {
// 从分数或等级计算绩点
fromScoreOrGradeLevel: function (score) {},
// 计算一门课程的学分绩点
creditGPA: function (lecture) {},
// 计算若干门课程的平均分
avgScore: function (lectures) {},
// 计算若干门课程的平均学分绩点
avgCreditGPA: function (lecutres) {},
// 计算若干门课程的加权平均分
avgWeightedScore: function (lectures) {}
};
// ## 课程成绩记录定义
//
// * code : 课程代码
// * name : 课程名称
// * type : 课程性质(公共基础?专业基础?)
// * attribution : 课程归属(人文社科?工程基础?)
// * is_minor : 是否是辅修专业课?
// * grade:
// - score : 课程成绩
// - makeup : 补考成绩
// - rework : 重修成绩
// * credit : 学分
// * gpa : 绩点
function Lecture() {
this.code = null;
this.name = null;
this.type = null;
this.attribution = null;
this.isMinor = false;
this.credit = 0.0;
this.grade = {
score: 0.0,
makeup: 0.0,
rework: 0.0
};
this.gpa = 0.0;
}
// 从 `table tr` 中获取一个课程信息
Lecture.fromTableRow = function (row) {
};
// 从 `table` 中获取一系列课程信息
Lecture.fromRows = function (table) {
};
测试先行
为了更好地确保代码是正确的,我们改变一下之前需求导向的写代码方法,改用测试导向的风格。
在助手这个项目中,我们选用了 mocha 和 should.js 来做测试。 (都是 TJ 大大的作品呢 OvO)
测试导向的开发流程比较有意思的地方在于我们不先写代码,而是先写测试;然后再写代码把这些测试跑通 —— 就可以算作我们的代码满足需求了。 鉴于此,我们会采用 BDD 的方式来描述助手的测试:
describe('page', function () {
describe('on', function () {
it('should return page for chain usage', function () {
var page = new Page;
page.on('test-page', testCallback).should.exactly(page);
});
});
});
写出这个测试之后,打开本地测试服务器查看运行结果;注意我们还没写具体的实现(严格来说是还没把这个实现写对):

然后我们再去完成实现具体的接口:
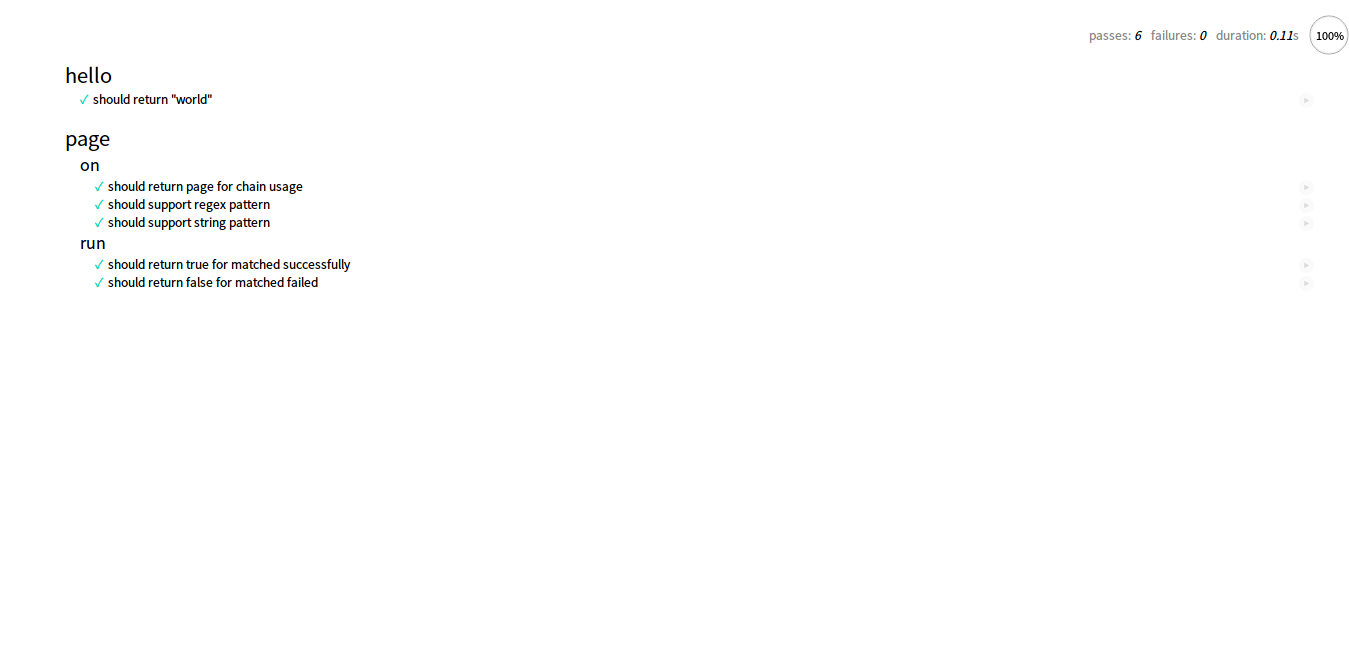
(成就感油然而生,掌声鼓励谢谢!:clap:)
这样我们就比较有信心进行其他修改啦:

问:这些 BDD / TDD 看起来好像很棒噢,我以后写代码是不是都应该这么做啊?
答:

在完成这些测试之后,我们就可以着手把之前的 DNA 双螺旋清理掉:
虽然代码好像变多了,但至少我们可以比较容易发现出问题是出现在哪里 —— 因为我们有测试保佑啦!
Recap 2
今天的重构过程中我们始终强调贯彻了以下几个原则:
- 在写代码前要先思考
- 要适当调整代码的组织结构,防止因为各部分紧耦合产生的 bad smell
- 尽可能保证有测试存在
并且加大了认真写代码的力度。
下一篇就写写怎么完成剩下的功能啦。